Go 博客
Go 程序性能分析
在 2011 年 Scala 大会(Scala Days 2011)上,Robert Hundt 发表了一篇题为《C++/Java/Go/Scala 中的循环识别》(Loop Recognition in C++/Java/Go/Scala.)的论文。该论文使用 C++、Go、Java 和 Scala 实现了一种特定的循环查找算法,类似于编译器流分析过程中使用的算法,然后利用这些程序得出关于这些语言典型性能关注点的结论。论文中展示的 Go 程序运行得相当慢,这为演示如何使用 Go 的性能分析工具将慢速程序变得更快提供了一个绝佳的机会。
通过使用 Go 的性能分析工具识别和纠正特定的瓶颈,我们可以使 Go 的循环查找程序运行速度提高一个数量级,内存使用量减少 6 倍。(更新:由于最近 `gcc` 中 `libstdc++` 的优化,内存使用量现在减少了 3.7 倍。)
Hundt 的论文没有具体说明他使用了哪些版本的 C++、Go、Java 和 Scala 工具。在这篇博文中,我们将使用 `6g` Go 编译器的最新周快照版本,以及 Ubuntu Natty 发行版附带的 `g++` 版本。(我们不使用 Java 或 Scala,因为我们不擅长用这两种语言编写高效的程序,所以比较会不公平。由于 C++ 在论文中是最快的语言,因此这里的 C++ 比较应该足够了。)(更新:在这篇更新的文章中,我们将使用 amd64 上 Go 编译器的最新开发快照版本,以及 `g++` 的最新版本——4.8.0,该版本于 2013 年 3 月发布。)
$ go version
go version devel +08d20469cc20 Tue Mar 26 08:27:18 2013 +0100 linux/amd64
$ g++ --version
g++ (GCC) 4.8.0
Copyright (C) 2013 Free Software Foundation, Inc.
...
$
程序运行在配置为 3.4GHz Core i7-2600 CPU 和 16 GB RAM 的计算机上,运行 Gentoo Linux 的 3.8.4-gentoo 内核。该机器的 CPU 频率缩放功能已禁用,通过
$ sudo bash
# for i in /sys/devices/system/cpu/cpu[0-7]
do
echo performance > $i/cpufreq/scaling_governor
done
#
我们从 Hundt 的 C++ 和 Go 基准测试程序(Hundt’s benchmark programs)中提取了代码,将每个程序合并到一个源文件中,并删除了除一行输出以外的所有输出。我们将使用 Linux 的 `time` 工具来计时程序,并采用一种显示用户时间、系统时间、实际时间以及最大内存使用量的格式。
$ cat xtime
#!/bin/sh
/usr/bin/time -f '%Uu %Ss %er %MkB %C' "$@"
$
$ make havlak1cc
g++ -O3 -o havlak1cc havlak1.cc
$ ./xtime ./havlak1cc
# of loops: 76002 (total 3800100)
loop-0, nest: 0, depth: 0
17.70u 0.05s 17.80r 715472kB ./havlak1cc
$
$ make havlak1
go build havlak1.go
$ ./xtime ./havlak1
# of loops: 76000 (including 1 artificial root node)
25.05u 0.11s 25.20r 1334032kB ./havlak1
$
C++ 程序运行耗时 17.80 秒,内存使用量为 700 MB。Go 程序运行耗时 25.20 秒,内存使用量为 1302 MB。(这些测量结果与论文中的结果难以调和,但本文的重点是探索如何使用 `go tool pprof`,而不是重现论文中的结果。)
为了开始优化 Go 程序,我们必须启用性能分析。如果代码使用了 Go 的 testing 包的基准测试支持,我们可以使用 gotest 标准的 `-cpuprofile` 和 `-memprofile` 标志。在像这样独立的程序中,我们必须导入 `runtime/pprof` 并添加几行代码。
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")
func main() {
flag.Parse()
if *cpuprofile != "" {
f, err := os.Create(*cpuprofile)
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
}
...
新代码定义了一个名为 `cpuprofile` 的标志,调用 Go 的 flag 库来解析命令行标志,然后,如果命令行中设置了 `cpuprofile` 标志,则将 CPU 性能分析重定向到该文件。性能分析器需要在程序退出前调用 `StopCPUProfile` 来刷新任何待写入文件的内容;我们使用 `defer` 来确保这一点在 `main` 函数返回时发生。
添加代码后,我们可以使用新的 `-cpuprofile` 标志运行程序,然后运行 `go tool pprof` 来解释分析结果。
$ make havlak1.prof
./havlak1 -cpuprofile=havlak1.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak1 havlak1.prof
Welcome to pprof! For help, type 'help'.
(pprof)
`go tool pprof` 程序是 Google 的 C++ 性能分析器 `pprof` 的一个变体。最重要的命令是 `topN`,它显示分析结果中排名前 `N` 的样本。
(pprof) top10
Total: 2525 samples
298 11.8% 11.8% 345 13.7% runtime.mapaccess1_fast64
268 10.6% 22.4% 2124 84.1% main.FindLoops
251 9.9% 32.4% 451 17.9% scanblock
178 7.0% 39.4% 351 13.9% hash_insert
131 5.2% 44.6% 158 6.3% sweepspan
119 4.7% 49.3% 350 13.9% main.DFS
96 3.8% 53.1% 98 3.9% flushptrbuf
95 3.8% 56.9% 95 3.8% runtime.aeshash64
95 3.8% 60.6% 101 4.0% runtime.settype_flush
88 3.5% 64.1% 988 39.1% runtime.mallocgc
启用 CPU 性能分析时,Go 程序大约每秒停止 100 次,并记录一个样本,该样本包含当前正在执行的 goroutine 堆栈上的程序计数器。分析结果包含 2525 个样本,因此程序运行了略多于 25 秒。在 `go tool pprof` 的输出中,每一行代表一个出现在样本中的函数。前两列显示函数运行时(相对于等待被调用的函数返回)的样本数,以原始计数和总样本百分比表示。`runtime.mapaccess1_fast64` 函数在 298 个样本中运行,占 11.8%。`top10` 输出按此样本计数排序。第三列显示列表中的运行总计:前三行占样本总数的 32.4%。第四列和第五列显示函数出现在样本中的次数(无论是正在运行还是等待被调用的函数返回)。`main.FindLoops` 函数在 10.6% 的样本中运行,但在调用堆栈上(它或它调用的函数正在运行)的样本占 84.1%。
要按第四列和第五列排序,请使用 `-cum`(代表累积)标志。
(pprof) top5 -cum
Total: 2525 samples
0 0.0% 0.0% 2144 84.9% gosched0
0 0.0% 0.0% 2144 84.9% main.main
0 0.0% 0.0% 2144 84.9% runtime.main
0 0.0% 0.0% 2124 84.1% main.FindHavlakLoops
268 10.6% 10.6% 2124 84.1% main.FindLoops
(pprof) top5 -cum
实际上,`main.FindLoops` 和 `main.main` 的总计应该为 100%,但每个堆栈样本仅包含底部 100 个堆栈帧;在约四分之一的样本中,递归函数 `main.DFS` 的深度超过 `main.main` 100 帧以上,因此完整的跟踪被截断了。
堆栈跟踪样本包含比文本列表更丰富的函数调用关系数据。`web` 命令以 SVG 格式写入性能分析数据图,并在 Web 浏览器中打开它。(还有一个 `gv` 命令,它写入 PostScript 并在 Ghostview 中打开它。对于这两个命令,都需要安装 graphviz。)
(pprof) web
下面是 完整图表 的一小部分。
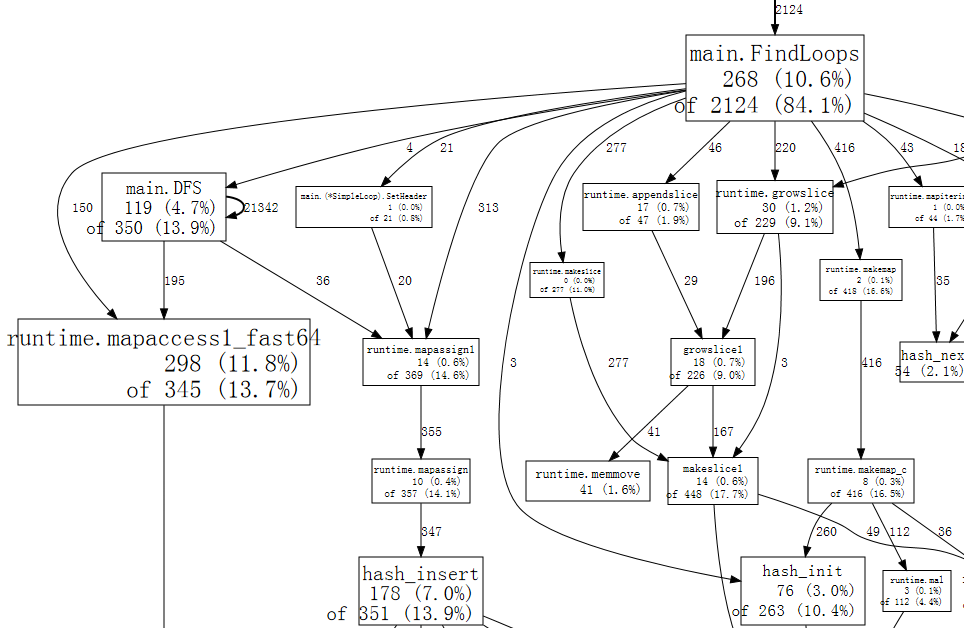
图中的每个框代表一个单独的函数,框的大小根据函数运行的样本数量确定。从框 X 到框 Y 的边表示 X 调用 Y;边上的数字表示该调用在样本中出现的次数。如果一个调用在单个样本中出现多次,例如在递归函数调用期间,则每次出现都会计入边的权重。这解释了 `main.DFS` 到其自身的自循环边上的 21342。
仅仅从图中,我们就可以看到程序花费了大量时间在哈希操作上,这对应于 Go 的 `map` 值的用法。我们可以告诉 `web` 命令只使用包含特定函数的样本,例如 `runtime.mapaccess1_fast64`,这可以清除图中的一些噪声。
(pprof) web mapaccess1
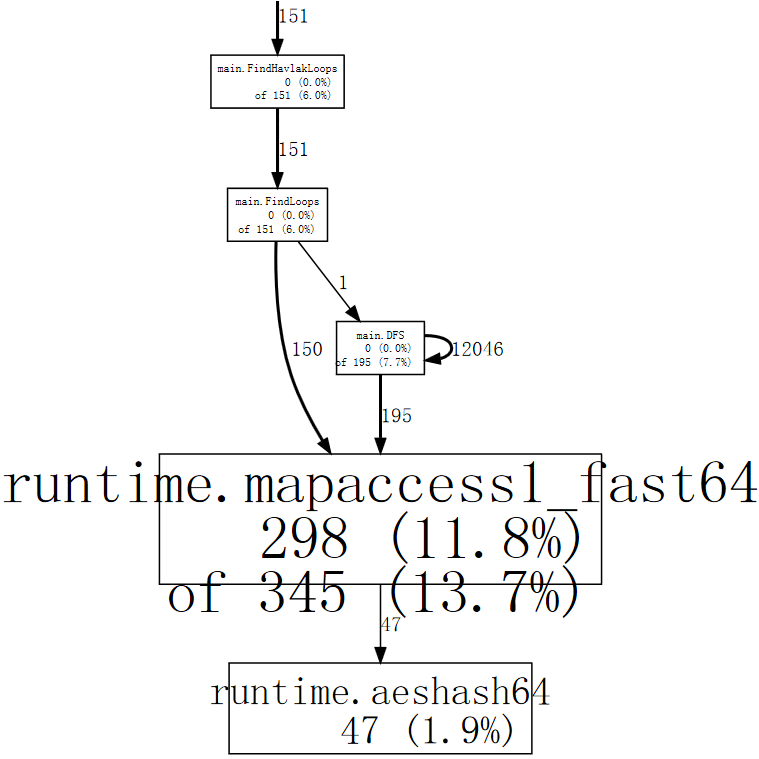
如果我们仔细观察,我们可以看到对 `runtime.mapaccess1_fast64` 的调用是由 `main.FindLoops` 和 `main.DFS` 发出的。
现在我们对大局有了一个大致的了解,是时候深入研究一个特定的函数了。让我们先看看 `main.DFS`,因为它是一个较短的函数。
(pprof) list DFS
Total: 2525 samples
ROUTINE ====================== main.DFS in /home/rsc/g/benchgraffiti/havlak/havlak1.go
119 697 Total samples (flat / cumulative)
3 3 240: func DFS(currentNode *BasicBlock, nodes []*UnionFindNode, number map[*BasicBlock]int, last []int, current int) int {
1 1 241: nodes[current].Init(currentNode, current)
1 37 242: number[currentNode] = current
. . 243:
1 1 244: lastid := current
89 89 245: for _, target := range currentNode.OutEdges {
9 152 246: if number[target] == unvisited {
7 354 247: lastid = DFS(target, nodes, number, last, lastid+1)
. . 248: }
. . 249: }
7 59 250: last[number[currentNode]] = lastid
1 1 251: return lastid
(pprof)
列表显示了 `DFS` 函数的源代码(实际上是匹配正则表达式 `DFS` 的所有函数的源代码)。前三列是运行该行时采取的样本数,运行该行或在调用该行的代码时采取的样本数,以及文件中的行号。相关的 `disasm` 命令显示函数的反汇编而不是源代码列表;当样本数足够时,这可以帮助您查看哪些指令成本高昂。`weblist` 命令混合了这两种模式:它显示 源代码列表,点击某一行会显示其反汇编。
由于我们已经知道时间花在了由哈希运行时函数实现的映射查找上,因此我们最关心第二列。大量的运行时间花在了对 `DFS` 的递归调用(第 247 行)上,这符合递归遍历的预期。排除递归,看起来时间花在了第 242、246 和 250 行的 `number` 映射的访问上。对于这种特定的查找,映射不是最有效的选择。正如在编译器中一样,基本块结构被分配了唯一的序号。我们可以使用 `[]int`(一个由块号索引的切片),而不是使用 `map[*BasicBlock]int`。当数组或切片可以胜任时,没有理由使用映射。
将 `number` 从映射更改为切片需要修改程序中的七行代码,并将运行时间缩短近一半。
$ make havlak2
go build havlak2.go
$ ./xtime ./havlak2
# of loops: 76000 (including 1 artificial root node)
16.55u 0.11s 16.69r 1321008kB ./havlak2
$
(请参阅 `havlak1` 和 `havlak2` 之间的 diff)
我们可以再次运行性能分析器来确认 `main.DFS` 不再是运行时的重要组成部分。
$ make havlak2.prof
./havlak2 -cpuprofile=havlak2.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak2 havlak2.prof
Welcome to pprof! For help, type 'help'.
(pprof)
(pprof) top5
Total: 1652 samples
197 11.9% 11.9% 382 23.1% scanblock
189 11.4% 23.4% 1549 93.8% main.FindLoops
130 7.9% 31.2% 152 9.2% sweepspan
104 6.3% 37.5% 896 54.2% runtime.mallocgc
98 5.9% 43.5% 100 6.1% flushptrbuf
(pprof)
`main.DFS` 条目不再出现在性能分析结果中,其余程序的运行时也已下降。现在程序大部分时间都在分配内存和垃圾回收(`runtime.mallocgc`,它同时进行分配和定期垃圾回收,占用了 54.2% 的时间)。要找出垃圾回收器运行如此频繁的原因,我们需要找出是什么在分配内存。一种方法是将内存分析添加到程序中。我们将安排,如果提供了 `-memprofile` 标志,程序将在循环查找执行一次迭代后停止,写入内存分析结果并退出。
var memprofile = flag.String("memprofile", "", "write memory profile to this file")
...
FindHavlakLoops(cfgraph, lsgraph)
if *memprofile != "" {
f, err := os.Create(*memprofile)
if err != nil {
log.Fatal(err)
}
pprof.WriteHeapProfile(f)
f.Close()
return
}
我们使用 `-memprofile` 标志调用程序来写入分析结果。
$ make havlak3.mprof
go build havlak3.go
./havlak3 -memprofile=havlak3.mprof
$
(请参阅 从 havlak2 的 diff)
我们使用 `go tool pprof` 的方式完全相同。现在我们正在检查的样本是内存分配,而不是时钟滴答。
$ go tool pprof havlak3 havlak3.mprof
Adjusting heap profiles for 1-in-524288 sampling rate
Welcome to pprof! For help, type 'help'.
(pprof) top5
Total: 82.4 MB
56.3 68.4% 68.4% 56.3 68.4% main.FindLoops
17.6 21.3% 89.7% 17.6 21.3% main.(*CFG).CreateNode
8.0 9.7% 99.4% 25.6 31.0% main.NewBasicBlockEdge
0.5 0.6% 100.0% 0.5 0.6% itab
0.0 0.0% 100.0% 0.5 0.6% fmt.init
(pprof)
`go tool pprof` 命令报告 `FindLoops` 分配了约 56.3 MB 的可用内存(总共 82.4 MB),`CreateNode` 占了另外 17.6 MB。为了减少开销,内存分析器仅记录每半兆字节分配的约一个块的信息(“1-in-524288 采样率”),因此这些是实际计数的近似值。
为了查找内存分配,我们可以列出那些函数。
(pprof) list FindLoops
Total: 82.4 MB
ROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go
56.3 56.3 Total MB (flat / cumulative)
...
1.9 1.9 268: nonBackPreds := make([]map[int]bool, size)
5.8 5.8 269: backPreds := make([][]int, size)
. . 270:
1.9 1.9 271: number := make([]int, size)
1.9 1.9 272: header := make([]int, size, size)
1.9 1.9 273: types := make([]int, size, size)
1.9 1.9 274: last := make([]int, size, size)
1.9 1.9 275: nodes := make([]*UnionFindNode, size, size)
. . 276:
. . 277: for i := 0; i < size; i++ {
9.5 9.5 278: nodes[i] = new(UnionFindNode)
. . 279: }
...
. . 286: for i, bb := range cfgraph.Blocks {
. . 287: number[bb.Name] = unvisited
29.5 29.5 288: nonBackPreds[i] = make(map[int]bool)
. . 289: }
...
看来当前的瓶颈与上一个相同:在可以使用更简单数据结构的场合使用了映射。`FindLoops` 分配了大约 29.5 MB 的映射。
顺带一提,如果我们使用 `--inuse_objects` 标志运行 `go tool pprof`,它将报告分配计数而不是大小。
$ go tool pprof --inuse_objects havlak3 havlak3.mprof
Adjusting heap profiles for 1-in-524288 sampling rate
Welcome to pprof! For help, type 'help'.
(pprof) list FindLoops
Total: 1763108 objects
ROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go
720903 720903 Total objects (flat / cumulative)
...
. . 277: for i := 0; i < size; i++ {
311296 311296 278: nodes[i] = new(UnionFindNode)
. . 279: }
. . 280:
. . 281: // Step a:
. . 282: // - initialize all nodes as unvisited.
. . 283: // - depth-first traversal and numbering.
. . 284: // - unreached BB's are marked as dead.
. . 285: //
. . 286: for i, bb := range cfgraph.Blocks {
. . 287: number[bb.Name] = unvisited
409600 409600 288: nonBackPreds[i] = make(map[int]bool)
. . 289: }
...
(pprof)
由于约 200,000 个映射占用了 29.5 MB,看来初始映射分配大约需要 150 字节。当映射用于保存键值对时,这是合理的,但当映射用作简单集合的占位符时,就不那么合理了,这里就是这种情况。
与其使用映射,不如使用一个简单的切片来列出元素。在几乎所有使用映射的情况下,算法都不可能插入重复元素。在最后一种情况中,我们可以编写一个简单的 `append` 内置函数的变体。
func appendUnique(a []int, x int) []int {
for _, y := range a {
if x == y {
return a
}
}
return append(a, x)
}
除了编写该函数之外,将 Go 程序中的映射更改为切片只需要更改几行代码。
$ make havlak4
go build havlak4.go
$ ./xtime ./havlak4
# of loops: 76000 (including 1 artificial root node)
11.84u 0.08s 11.94r 810416kB ./havlak4
$
(请参阅 从 havlak3 的 diff)
我们现在的速度比开始时快了 2.11 倍。让我们再次查看 CPU 分析结果。
$ make havlak4.prof
./havlak4 -cpuprofile=havlak4.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak4 havlak4.prof
Welcome to pprof! For help, type 'help'.
(pprof) top10
Total: 1173 samples
205 17.5% 17.5% 1083 92.3% main.FindLoops
138 11.8% 29.2% 215 18.3% scanblock
88 7.5% 36.7% 96 8.2% sweepspan
76 6.5% 43.2% 597 50.9% runtime.mallocgc
75 6.4% 49.6% 78 6.6% runtime.settype_flush
74 6.3% 55.9% 75 6.4% flushptrbuf
64 5.5% 61.4% 64 5.5% runtime.memmove
63 5.4% 66.8% 524 44.7% runtime.growslice
51 4.3% 71.1% 51 4.3% main.DFS
50 4.3% 75.4% 146 12.4% runtime.MCache_Alloc
(pprof)
现在,内存分配和由此产生的垃圾回收(`runtime.mallocgc`)占用了我们运行时间的 50.9%。另一种查看系统垃圾回收原因的方法是查看导致回收的分配,即花费大部分时间在 `mallocgc` 上的那些分配。
(pprof) web mallocgc
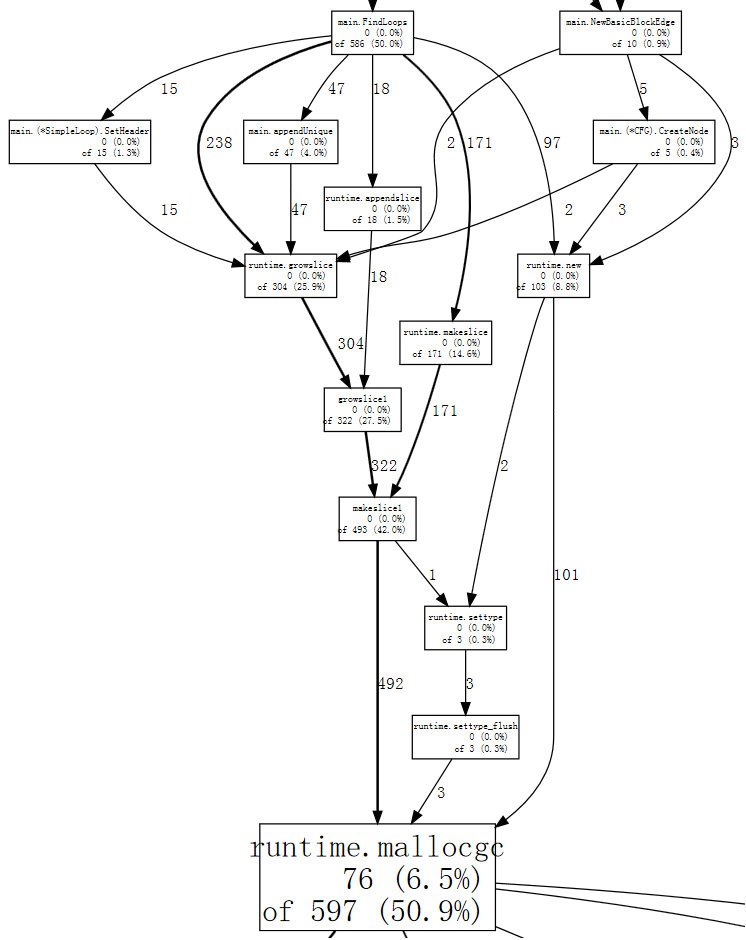
很难弄清楚图中的情况,因为有许多样本数较小的节点遮挡了较大的节点。我们可以告诉 `go tool pprof` 忽略那些不占总样本 10% 以上的节点。
$ go tool pprof --nodefraction=0.1 havlak4 havlak4.prof
Welcome to pprof! For help, type 'help'.
(pprof) web mallocgc
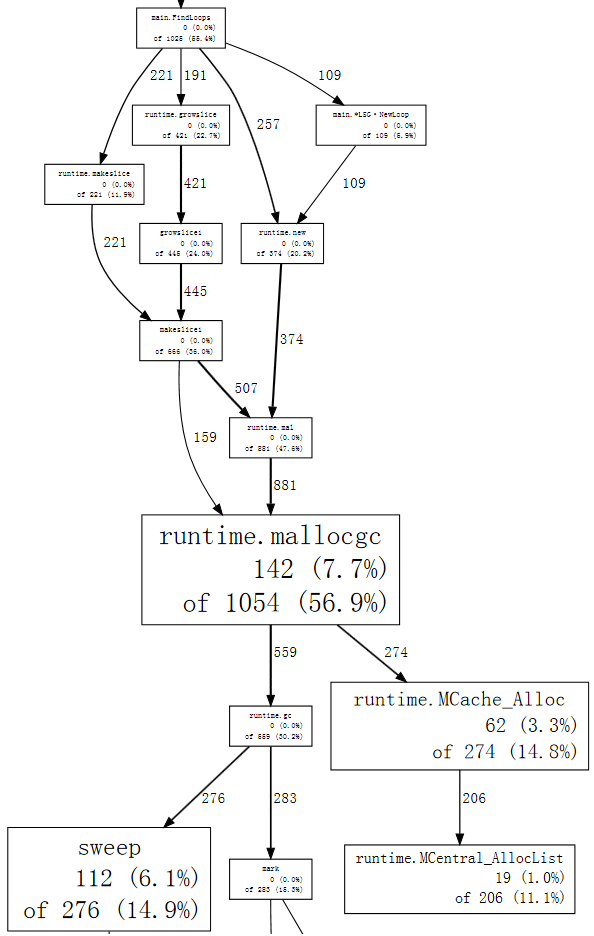
现在我们可以轻松地跟踪粗箭头,发现 `FindLoops` 触发了大部分垃圾回收。如果我们列出 `FindLoops`,我们会发现它大部分时间都花在了开头。
(pprof) list FindLoops
...
. . 270: func FindLoops(cfgraph *CFG, lsgraph *LSG) {
. . 271: if cfgraph.Start == nil {
. . 272: return
. . 273: }
. . 274:
. . 275: size := cfgraph.NumNodes()
. . 276:
. 145 277: nonBackPreds := make([][]int, size)
. 9 278: backPreds := make([][]int, size)
. . 279:
. 1 280: number := make([]int, size)
. 17 281: header := make([]int, size, size)
. . 282: types := make([]int, size, size)
. . 283: last := make([]int, size, size)
. . 284: nodes := make([]*UnionFindNode, size, size)
. . 285:
. . 286: for i := 0; i < size; i++ {
2 79 287: nodes[i] = new(UnionFindNode)
. . 288: }
...
(pprof)
每次调用 `FindLoops` 时,它都会分配一些相当大的簿记结构。由于基准测试调用 `FindLoops` 50 次,这些累加起来就产生了大量的垃圾,因此也为垃圾回收器带来了大量工作。
拥有一个垃圾回收语言并不意味着你可以忽略内存分配问题。在这种情况下,一个简单的解决方案是引入一个缓存,以便每次调用 `FindLoops` 时都可以重用前一次调用的存储(如果可能)。(实际上,在 Hundt 的论文中,他解释说 Java 程序只需要进行此项更改即可获得合理的性能,但他在其他垃圾回收实现中并未进行相同的更改。)
我们将添加一个全局 `cache` 结构。
var cache struct {
size int
nonBackPreds [][]int
backPreds [][]int
number []int
header []int
types []int
last []int
nodes []*UnionFindNode
}
然后让 `FindLoops` 在分配时咨询它作为替代。
if cache.size < size {
cache.size = size
cache.nonBackPreds = make([][]int, size)
cache.backPreds = make([][]int, size)
cache.number = make([]int, size)
cache.header = make([]int, size)
cache.types = make([]int, size)
cache.last = make([]int, size)
cache.nodes = make([]*UnionFindNode, size)
for i := range cache.nodes {
cache.nodes[i] = new(UnionFindNode)
}
}
nonBackPreds := cache.nonBackPreds[:size]
for i := range nonBackPreds {
nonBackPreds[i] = nonBackPreds[i][:0]
}
backPreds := cache.backPreds[:size]
for i := range nonBackPreds {
backPreds[i] = backPreds[i][:0]
}
number := cache.number[:size]
header := cache.header[:size]
types := cache.types[:size]
last := cache.last[:size]
nodes := cache.nodes[:size]
当然,这样的全局变量是不好的工程实践:它意味着并发调用 `FindLoops` 现在是不安全的。目前,我们只进行最少的更改,以了解程序性能的关键因素;此更改很简单,并且模仿了 Java 实现中的代码。Go 程序的最终版本将使用一个单独的 `LoopFinder` 实例来跟踪此内存,恢复了并发使用的可能性。
$ make havlak5
go build havlak5.go
$ ./xtime ./havlak5
# of loops: 76000 (including 1 artificial root node)
8.03u 0.06s 8.11r 770352kB ./havlak5
$
(请参阅 从 havlak4 的 diff)
我们还可以做更多工作来清理程序并使其更快,但所有这些都不需要我们尚未展示的性能分析技术。内部循环中使用的 work list 可以在迭代之间和调用 `FindLoops` 之间重用,并且可以与该传递过程中生成的单独的“节点池”结合使用。同样,循环图存储可以在每次迭代时重用,而不是重新分配。除了这些性能改进之外,最终版本使用了惯用的 Go 风格编写,并使用了数据结构和方法。风格上的改变对运行时间影响很小:算法和约束保持不变。
最终版本运行耗时 2.29 秒,内存使用量为 351 MB。
$ make havlak6
go build havlak6.go
$ ./xtime ./havlak6
# of loops: 76000 (including 1 artificial root node)
2.26u 0.02s 2.29r 360224kB ./havlak6
$
这比我们开始时使用的程序快了 11 倍。即使我们禁用生成的循环图的重用,只缓存循环查找簿记信息,程序仍然比原始程序快 6.7 倍,内存使用量减少 1.5 倍。
$ ./xtime ./havlak6 -reuseloopgraph=false
# of loops: 76000 (including 1 artificial root node)
3.69u 0.06s 3.76r 797120kB ./havlak6 -reuseloopgraph=false
$
当然,现在将这个 Go 程序与原始 C++ 程序进行比较已经不公平了,因为原始 C++ 程序使用了像 `set` 这样效率低下的数据结构,而 `vector` 会更合适。作为一项健全性检查,我们将最终的 Go 程序翻译成了等效的 C++ 代码。其执行时间与 Go 程序相似。
$ make havlak6cc
g++ -O3 -o havlak6cc havlak6.cc
$ ./xtime ./havlak6cc
# of loops: 76000 (including 1 artificial root node)
1.99u 0.19s 2.19r 387936kB ./havlak6cc
Go 程序运行速度几乎与 C++ 程序一样快。由于 C++ 程序使用自动删除和分配而不是显式缓存,因此 C++ 程序稍短且易于编写,但并非戏剧性地如此。
$ wc havlak6.cc; wc havlak6.go
401 1220 9040 havlak6.cc
461 1441 9467 havlak6.go
$
(请参阅 havlak6.cc 和 havlak6.go)
基准测试仅与其衡量的程序一样好。我们使用 `go tool pprof` 研究了一个效率低下的 Go 程序,然后通过一个数量级提高了其性能,并将内存使用量减少了 3.7 倍。随后与等效优化的 C++ 程序进行比较表明,当程序员在内部循环中生成的垃圾量方面做到仔细时,Go 可以与 C++ 竞争。
用于编写本文的程序源文件、Linux x86-64 二进制文件和性能分析结果可在 GitHub 上的 benchgraffiti 项目中找到。
如上所述,`go test` 已经包含了这些性能分析标志:定义一个 benchmark 函数,您就准备好了。还有一个标准的 HTTP 接口可用于访问性能分析数据。在 HTTP 服务器中,添加
import _ "net/http/pprof"
将在 ` /debug/pprof/` 下安装一些 URL 的处理程序。然后,您可以使用单个参数运行 `go tool pprof`——即指向您服务器性能分析数据的 URL,它将下载并检查实时分析结果。
go tool pprof https://:6060/debug/pprof/profile # 30-second CPU profile
go tool pprof https://:6060/debug/pprof/heap # heap profile
go tool pprof https://:6060/debug/pprof/block # goroutine blocking profile
goroutine 阻塞分析将在以后的文章中介绍。敬请关注。